

Przedziwny sposób, w jaki sztuczna inteligencja rozumie obrazy
Zobaczcie świat oczami Sztucznej Inteligencji. Sprawdźcie, jak sztuczny “mózg” postrzega rzeczywistość. My zauważamy plamy, linie, kolory, a SI… Sami się przekonacie czytając opowieść Łukasza Kuncewicza z firmy Enigma Pattern Inc., który niczym patolog kroi zaprogramowany przez samego siebie sztuczny mózg.
Moja praca polega na opiekowaniu się sztucznymi sieciami neuronowymi i uczeniu ich. Przez osiem godzin dostarczam im bodźców i tworzę im warunki do rozwoju. Po skończonej pracy zaś wracam do domu, gdzie… dokładnie to samo czeka moje dwie nieco bardziej naturalne sieci neuronowe, zwane przez resztę rodziny moimi dziećmi. I muszę powiedzieć, że ta opieka raz nad sztucznymi, raz nad naturalnymi sieciami neuronowymi, powoduje takie śmieszne uczucie, coś w stylu déjà vu, które prowadzi czasami do całkiem poważnych pytań…
Podam Wam pierwszy z brzegu przykład: patrzę na swoją niedawno urodzoną córeczkę i obserwuję, jak z dnia na dzień zaczyna odróżniać najpierw dzień od nocy, potem rzeczy jasne od ciemnych, jak zaczyna reagować na ludzkie kształty, aż w końcu umie odróżnić mamę od taty.
I patrzę na moje sieci neuronowe w pracy, na modele do opisu obrazków i widzę jak najpierw uczą się zwracać uwagę na podstawowe elementy obrazka takie jak jasność czy kontrast, potem używają tych elementarnych umiejętności do uczenia się kształtów, wzorów, aż w końcu radzą sobie z tak skomplikowanymi zadaniami jak odróżnianie roweru od samochodu, kota od psa, kobiety od mężczyzny. Mamy od taty.
Można oczywiście takie podobieństwa zbyć wzruszeniem ramion. Albo potraktować je poważnie. Jeśli macie ochotę, zapraszam Was do wspólnej wędrówki po sieci neuronowej. Na chwilę zostaniemy chirurgami i będziemy wycinać warstwy elektronicznego mózgu w nadziei na uzyskanie odpowiedzi na nękające mnie pytania: czy naprawdę aż tak bardzo się różnimy od maszyn? Czy maszyna widzi coś innego, niż my? Jeśli tak, to co widzi? Kropki, linie, kształty, wzory? A co jeśli widzi coś więcej? Co to jest, to więcej? Czy czegoś nam, ludziom, brakuje i nawet o tym nie wiemy?
Jak zostać elektronicznym neurochirurgiem?
Po pierwsze, potrzebujemy sztucznego mózgu. Użyjemy zatem VGG19 – standardowej obecnie sieci neuronowej, wyspecjalizowanej w rozpoznawaniu obrazów. Taka sieć to tak naprawdę bardzo skomplikowana matematyczna funkcja, która na wejściu przyjmuje obrazek (matrycę pikseli) i przetwarza ją w opis tego, co jest na obrazku.
Funkcja ta zbudowana jest ze sztucznych neuronów, takich matematycznych obiektów, które naśladują zachowanie naszych prawdziwych, zwierzęcych neuronów. Neurony w VGG19 pogrupowane są w warstwy, które mają swoją kolejność. Informacja (piksele z obrazka) przepływa przez VGG19 od warstwy początkowej (pierwszej), poprzez kolejne warstwy wewnętrzne aż do warstwy końcowej, która określa co jest na obrazku. Dla przykładu, weźmy sobie zdjęcie krajobrazu i poprośmy VGG19 o jego ocenę:
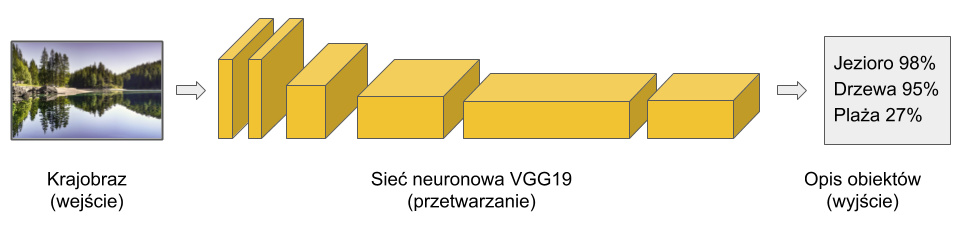
Przykład działania sieci VGG opisującej obrazek.
No dobrze, ale jak zatem zostać elektroniczny neurochirurgiem? Zanim zaczniemy kroić VGG19, zatrzymajmy się chwilę nad zagadnieniem odczuwania. Weźmy dowolny obrazek, który wywołuje u nas uczucia. Np. Pejzaż z kamiennym mostem Rembrandta. Patrząc na ten obraz czuję spokój, smutek i nostalgię. Co się wtedy dzieje w moim mózgu? Obraz pobudza niektóre neurony, niektóre wycisza – i ten konkretny stan ich aktywacji odczuwam właśnie jako spokój, smutek i nostalgię.
W analogiczny sposób, jeśli przepuszczę ten obraz przez VGG19, niektóre sztuczne neurony w tej sieci on pobudzi, a niektóre wyciszy. Informacja z obrazu (kolory pikseli) przejdą poprzez kolejne warstwy, odpowiednio ustawiając stan sztucznych neuronów.

Pejzaż z kamiennym mostem, Rembrandt Harmenszoon van Rijn, 1637.
To oznacza, że nasza VGG19, gdy pokazujemy jej obraz Rembrandta, generuje tak naprawdę dwa rodzaje informacji: o tym, które jej neurony są pobudzone lub wyciszone i o tym, co jest na obrazku. I to daje nam unikalną możliwość wygenerowania specjalnego kolażu z tych dwóch zupełnie różnych obrazków. Takiego, który z jednej strony będzie zawierał te same obiekty co nasz użyty już poprzednio krajobraz (Jezioro 98%, Drzewa 95%, Plaża 27%, itd.), a z drugiej strony aktywującego i wyciszającego te same neurony, co podczas patrzenia na obraz Rembrandta. To trochę tak, jakby poprosić jakiegoś malarza, żeby namalował nam obrazek z takimi samymi obiektami, jakie ma nasz krajobraz i dające nam to samo uczucie (pobudzenie neuronów), które towarzyszy nam, kiedy patrzymy na dzieło Rembrandta.
Brzmi trochę jak bajka, ale efekty są jak najbardziej prawdziwe:

Przykład działania metody Style Transfer.
Tutaj prezentuję powiększoną wersję poprzedniego obrazka, żeby można było podziwiać kunszt VGG19 w całej okazałości. Jest krajobraz, ale jest także spokój, smutek i nostalgia, prawda?

Styl Rembrandta nałożony na fotografię.
Ta metoda tworzenia kolaży ma swoją oficjalną nazwę: Style Transfer i może być ona użyta do sprawdzania, co dzieje się na poszczególnych warstwach VGG19. Przykładowo, jeśli dana warstwa jest wrażliwa tylko na linie (nie na punkty, nie na plamy, nie na wzory, itd.), to nawet jeśli pokażemy jej najładniejszy na świecie krajobraz, to będzie go i tak malowała tylko liniami – bo tylko linie pobudzają jej neurony, tylko linie są tym czymś, co czuje. Więc izolując poszczególne warstwy VGG19 (cóż to dla nas, elektronicznych neurochirurgów) i prosząc je o narysowanie krajobrazu, będziemy widzieli co te warstwy czują, na co zwracają uwagę.

Linia poprzeczna, Wassily Kandinsky, 1923
I jeszcze ostatnia informacja – zamieńmy obraz Rembrandta na znacznie prostsze dzieło Kandinskiego – wtedy analiza umiejętności poszczególnych warstw będzie łatwiejsza.
Do dzieła. Czas pokroić VGG19!
Mamy naszą pierwszą warstwę. Jak widać, warstwa ta skupia się głównie na punktach. Mają one wszystkie ten sam rozmiar, warstwa nie umie rozróżniać ich wielkości. Warstwa ma także problemy z kolorami – jest w stanie użyć tylko tych kolorów, które występują na obrazie Kandinskiego. Nie umie także ich mieszać. Jak widać, umiejętności pierwszej warstwy są w zasadzie minimalne.

nterpretacja pejzażu wykonana przez pierwszą warstwę sieci VGG.
Druga warstwa używa elementów z warstwy pierwszej i jej umiejętności są już większe. Z kropek tworzy linie. Jeśli powiększylibyśmy ten obraz do dużych rozmiarów, byłoby widać, że linie są do siebie prostopadłe. Oznacza to, że warstwa umie rozpoznawać kąty proste. Nadal jednak linie mają tą samą grubość. Obrazek zaczyna mieć detale (np. ma gałęzie na drzewach), a to oznacza, że druga warstwa jest już w stanie zauważać szczegóły. Kolory nadal są niewłaściwe, ale widać, że SI radzi sobie z mieszaniem kolorów, widać płynne przejścia (gradienty) z jednego koloru do drugiego.

Warstwa druga
Umiejętności warstwy trzeciej są jeszcze bardziej wyrafinowane. Linie mają już różną grubość, są wobec siebie ustawione pod różnymi kątami. Kolory nadal są złe, ale zaczynają się delikatne wzory na plamach kolorów – to znaczy, że warstwa trzecia jest w stanie je rozpoznać. Neurony tej warstwy są ich świadome. Wynikowy obraz zaczyna także trochę przypominać obraz Kandinskiego – gdzieś delikatnie przebija przez niego prostota i konkret w malowaniu krajobrazu.

Warstwa trzecia
Te trzy pierwsze warstwy pokazują nam, że sieć zdążyła się już nauczyć kropek, linii, plam, gradientów i wzorów. Czyli tego, co my, ludzie, jesteśmy w stanie rozpoznać. A przed nami jeszcze kolejne warstwy… Odważamy się przejść do następnych warstw? Zobaczyć coś, czego dosłownie ludzkie oko jeszcze nie widziało?

Warstwa czwarta
Cóż, pierwszą moją reakcją była myśl: No, w końcu czwarta warstwa zaczęła dobierać dobre kolory. Las jest zielony, a jezioro niebieskie!. Jakże się myliłem.
W tym całym ferworze sprawdzania warstw zapomniałem, że pierwsze 3 warstwy tworzyły obrazki z błędnymi kolorami dokładnie dlatego, że na kolory zwracały uwagę. Patrzyły na obraz Kandinskiego, czuły jego kolorystykę i dlatego używały takich a nie innych kolorów. A teraz warstwa czwarta właśnie przestała. Jest już ponad kolorami. Kolory jej już nie obchodzą.
Patrząc na obrazek, która wygenerowała ta warstwa, można także zauważyć dziwne wzory na niebie – tak ta warstwa odczuwa, dosyć nudne dla nas, płaszczyzny tego samego koloru. Patrzy na niebo, patrzy na obraz Kandinskiego i używa elementów z Kandinskiego które powodują te same uczucia, co kiedy patrzy na niebo.
Na początku trudno to zrozumieć, ale przypomnijcie sobie postać Rain Mana. My patrzymy na niebo i widzimy tylko nudną, niebieską plamę – ale on być może widzi więcej… Jeśli zapytamy go, co widzi, zacznie nam mówić o liniach, kratkach, falach. Tak właśnie widzi się niebo, jeśli wyjdziemy poza kropki, linie, plamy, gradienty i wzory. Poza to, co dostępne dla człowieka.
Może jeszcze jedna próba wyjaśnienia tego fenomenu… Załóżmy przez chwilę, że jestem ślepy od urodzenia i poproszę Was o opisanie mi nieba. Pewnie usłyszałbym coś w stylu: no wiesz, jest takie niebieskie, jak woda w jeziorze… i ma chmury, takie białe pierzaste kłębki, podobne do owieczek. I to wyjaśnienie totalnie by mnie zmyliło. Bo ja słyszałem już kiedyś niebo, słyszałem jezioro, słyszałem także owce i jestem gotów przysiąc, że jak odczuwam niebo, to nie ma tam nic z jeziora czy owiec. Czemu w ogóle mówicie coś o jeziorze i owcach? Niebo nie chlupocze ani nie beczy… Trochę to bez sensu z Waszej strony, prawda?
Tak właśnie wygląda nasza komunikacja z czwartą warstwą. Ona stara się ślepemu powiedzieć, jak odczuwa niebo, a ślepiec się dziwi, skąd się tam pojawiają linie i kratki…
Nie będę Was mamił, nie rozumiem co się dzieje w warstwie czwartej i w warstwach po niej następujących. Proponuje po prostu na nie popatrzeć, podziwiać jak wspinają się na coraz większy poziom abstrakcji, poziom, którego (na razie) nie rozumiemy. Jak obraz jest coraz mniej „Kandinski”, bo to, jak my odbieramy obraz Kandinskiego i jak odbierają je wyższe warstwy coraz bardziej się rozmija. Jak coraz mniejszą wagę przywiązują do kolorów czy szczegółów, jak coraz więcej rysują „ponad” obrazkiem. Jak widzą świat. Jak mógłby wyglądać nasz świat, gdybyśmy mieli ich umiejętności.

Warstwa piąta

Warstwa szósta

Warstwa siódma

Warstwa ósma
Jakie to uczucie, wiedzieć że się umie… mniej?
To już koniec naszej wspólnej misji. Kroiliśmy sztuczny mózg, zajrzeliśmy do jego środka, zobaczyliśmy co on czuje i umie. Część jego umiejętności rozpoznaliśmy. Części nie zrozumieliśmy. Czujecie się lekko oszołomieni? Ja na pewno…
Z jednej strony to jest budujące, że my ludzie i Sztuczna Inteligencja mamy wspólną bazę umiejętności, że nawet tak prosty model jak VGG19 uczy się tych samych rzeczy, które i my poznajemy podczas naszego rozwoju. Z drugiej strony to jest jednak trochę straszne, że on idzie dalej. Że widzi więcej i czuje więcej. Magiczne pytanie więc brzmi: czy powinniśmy zacząć się bać Sztucznej Inteligencji? Czas pokaże.
Użytkownik Endinajla edytował ten post 22.12.2018 - 23:45







































